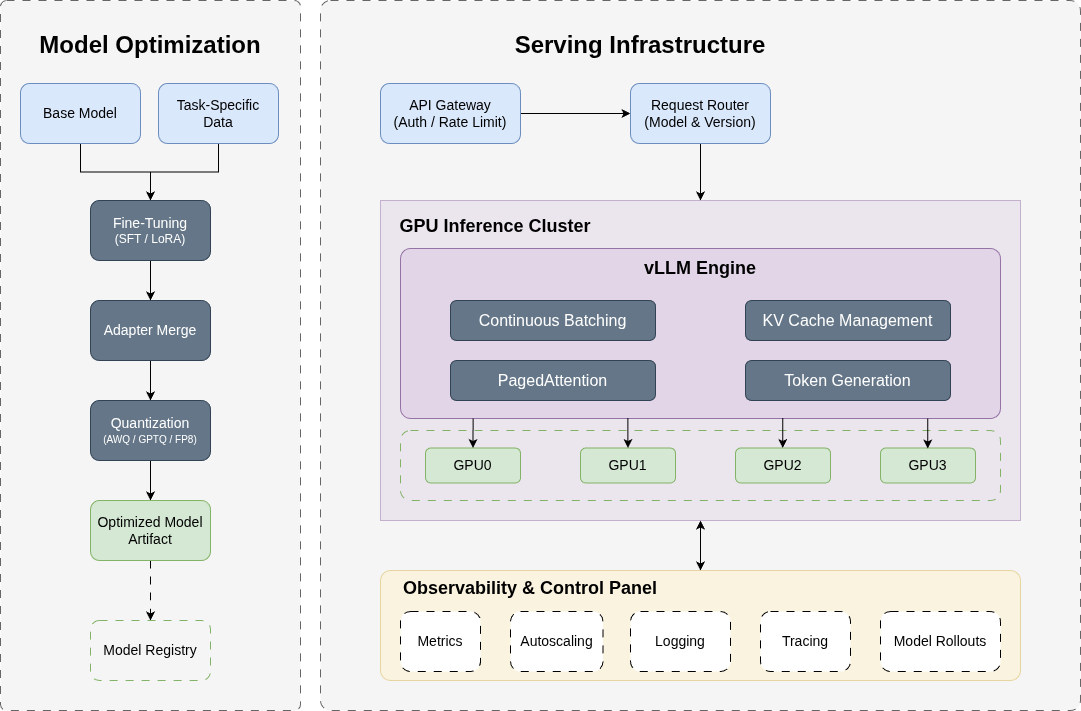
Benchmarked with vLLM (v0.18.0) serving engine.
Prefix caching was turned off for all benchmarks.
Model: NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 | GPU: B200
Endpoint: localhost:8000/v1/chat/completions | Max tokens: 256
| Concurrency |
Requests |
TTFT p50 (ms) |
TTFT p99 (ms) |
TPOT p50 (ms) |
TPOT p99 (ms) |
E2E p50 (ms) |
tok/s |
req/s |
Avg In |
Avg Out |
| 4 |
16 |
116.7 |
122.1 |
6.4 |
6.4 |
1737 |
589 |
2.3 |
343 |
256 |
| 8 |
32 |
117.9 |
126.5 |
7.6 |
7.6 |
2064 |
991 |
3.9 |
348 |
256 |
| 16 |
64 |
154.5 |
164.4 |
8.7 |
8.8 |
2372 |
1725 |
6.7 |
347 |
256 |
| 32 |
128 |
287.3 |
356.1 |
11.0 |
11.6 |
3082 |
2652 |
10.4 |
348 |
256 |
| 64 |
256 |
465.8 |
600.2 |
14.1 |
15.7 |
4072 |
4000 |
15.6 |
348 |
256 |
Model: Qwen3-30B-A3B-Instruct-2507-FP8 | GPU: H100 NVL
Endpoint: localhost:8000/v1/chat/completions | Max tokens: 256
| Concurrency |
Requests |
TTFT p50 (ms) |
TTFT p99 (ms) |
TPOT p50 (ms) |
TPOT p99 (ms) |
E2E p50 (ms) |
tok/s |
req/s |
Avg In |
Avg Out |
| 4 |
16 |
197.7 |
205.5 |
7.2 |
7.2 |
2031 |
508 |
2.0 |
331 |
256 |
| 8 |
32 |
211.5 |
225.3 |
8.4 |
8.6 |
2348 |
869 |
3.4 |
336 |
256 |
| 16 |
64 |
258.4 |
335.6 |
9.9 |
10.7 |
2787 |
1465 |
5.7 |
336 |
256 |
| 32 |
128 |
374.7 |
510.3 |
11.9 |
13.2 |
3426 |
2385 |
9.3 |
336 |
256 |
| 64 |
256 |
464.2 |
911.9 |
15.1 |
16.3 |
4316 |
3776 |
14.8 |
336 |
256 |
Model: Qwen3-30B-A3B-Instruct-2507-FP8 | GPU: NVIDIA RTX 6000 Ada
Endpoint: localhost:8000/v1/chat/completions | Max tokens: 256
| Concurrency |
Requests |
TTFT p50 (ms) |
TTFT p99 (ms) |
TPOT p50 (ms) |
TPOT p99 (ms) |
E2E p50 (ms) |
tok/s |
req/s |
Avg In |
Avg Out |
| 4 |
16 |
88.8 |
97.9 |
12.3 |
12.5 |
3217 |
318 |
1.2 |
331 |
256 |
| 8 |
32 |
126.2 |
168.8 |
15.6 |
15.9 |
4104 |
498 |
1.9 |
336 |
256 |
| 16 |
64 |
206.1 |
302.8 |
19.9 |
20.4 |
5281 |
774 |
3.0 |
336 |
256 |
| 32 |
128 |
305.9 |
591.0 |
25.2 |
26.0 |
6719 |
1217 |
4.8 |
336 |
256 |
| 64 |
256 |
433.3 |
1298.3 |
31.8 |
35.4 |
8639 |
1869 |
7.3 |
336 |
256 |
Model: Qwen3-32B-FP8 | GPU: H100 NVL
Endpoint: localhost:8000/v1/chat/completions | Max tokens: 256
| Concurrency |
Requests |
TTFT p50 (ms) |
TTFT p99 (ms) |
TPOT p50 (ms) |
TPOT p99 (ms) |
E2E p50 (ms) |
tok/s |
req/s |
Avg In |
Avg Out |
| 4 |
16 |
194.1 |
224.3 |
24.5 |
24.7 |
6429 |
159 |
0.6 |
331 |
256 |
| 8 |
32 |
372.4 |
421.5 |
24.8 |
25.9 |
6686 |
306 |
1.2 |
336 |
256 |
| 16 |
64 |
627.7 |
829.2 |
26.1 |
28.0 |
7275 |
562 |
2.2 |
336 |
256 |
| 32 |
128 |
735.6 |
1652.3 |
29.7 |
32.3 |
8340 |
977 |
3.8 |
336 |
256 |
| 64 |
256 |
1170.5 |
3219.5 |
37.3 |
41.0 |
10762 |
1532 |
6.0 |
336 |
256 |
Model: Qwen3-32B-FP8 | GPU: NVIDIA RTX 6000 Ada
Endpoint: localhost:8000/v1/chat/completions | Max tokens: 256
| Concurrency |
Requests |
TTFT p50 (ms) |
TTFT p99 (ms) |
TPOT p50 (ms) |
TPOT p99 (ms) |
E2E p50 (ms) |
tok/s |
req/s |
Avg In |
Avg Out |
| 4 |
16 |
556.2 |
595.6 |
48.2 |
49.7 |
12825 |
80 |
0.3 |
331 |
256 |
| 8 |
32 |
1007.4 |
1185.5 |
50.0 |
53.6 |
13795 |
148 |
0.6 |
336 |
256 |
| 16 |
64 |
1666.0 |
2453.4 |
54.0 |
60.0 |
15481 |
264 |
1.0 |
336 |
256 |
| 32 |
128 |
2329.6 |
4406.1 |
61.2 |
69.0 |
17913 |
456 |
1.8 |
336 |
256 |
| 64 |
256 |
4929.9 |
14339.0 |
92.2 |
152.1 |
28461 |
525 |
2.1 |
336 |
256 |