Agent Benchmark
Agent evaluation across multiple QA datasets, with granular control over models, prompts, tools and memory as well as traces and metrics capturing with an agentic system built on top of smolagents.
Simple QA
A subset of 50 short factual questions from the smolagents/benchmark-v1 dataset. Questions ask for specific facts (names, dates, numbers) that typically require web search or Wikipedia lookup. Answers are short — usually a 4-digit year or a proper noun. Each entry includes reference URLs in true_reasoning for verification.
Example: "What year was the municipality of Ramiriquí, Boyacá, Colombia, founded?" → 1541
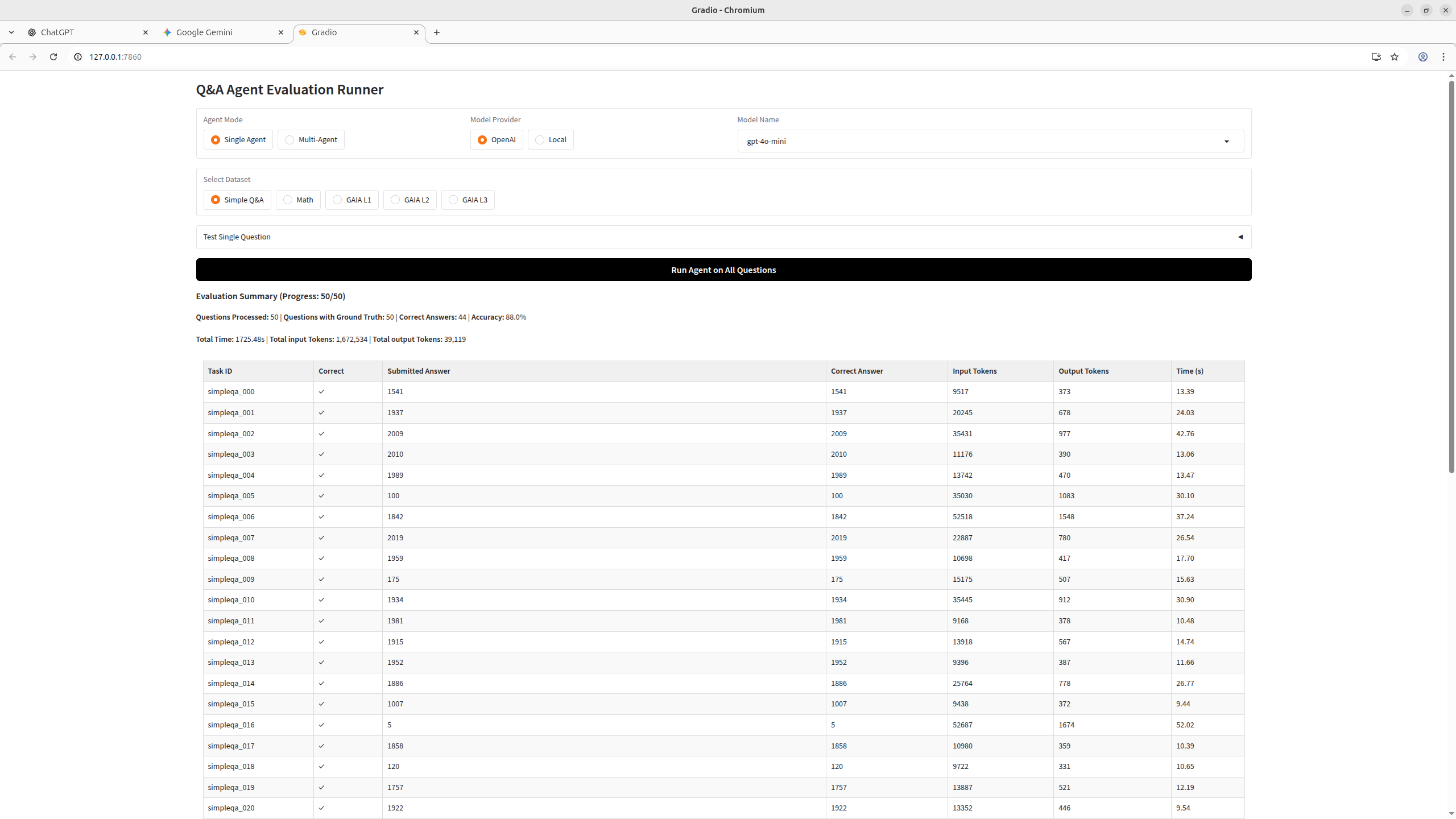
Results
| Model | Agent | Score |
|---|---|---|
| Gemini-2.5-flash | Code Agent | 46/50 |
| Qwen3.5-4B | Code Agent | 45/50 |
| Nemotron-3-Super-120B-A12B-NVFP4 | Code Agent | 38/50 |
Simple Math
A subset of 50 competition-style math problems from the same smolagents benchmark, originally sourced from the MATH dataset (Hendrycks et al.). Problems cover algebra, number theory, geometry, and combinatorics, often with LaTeX/Asymptote diagrams. Answers are numeric. Each entry includes a full worked solution in true_reasoning.
Example: "Rick is thinking of a positive factor of 14 and Steve is thinking of a positive factor of 42. If they are thinking of the same number, how many possible numbers could they be thinking of?" → 4
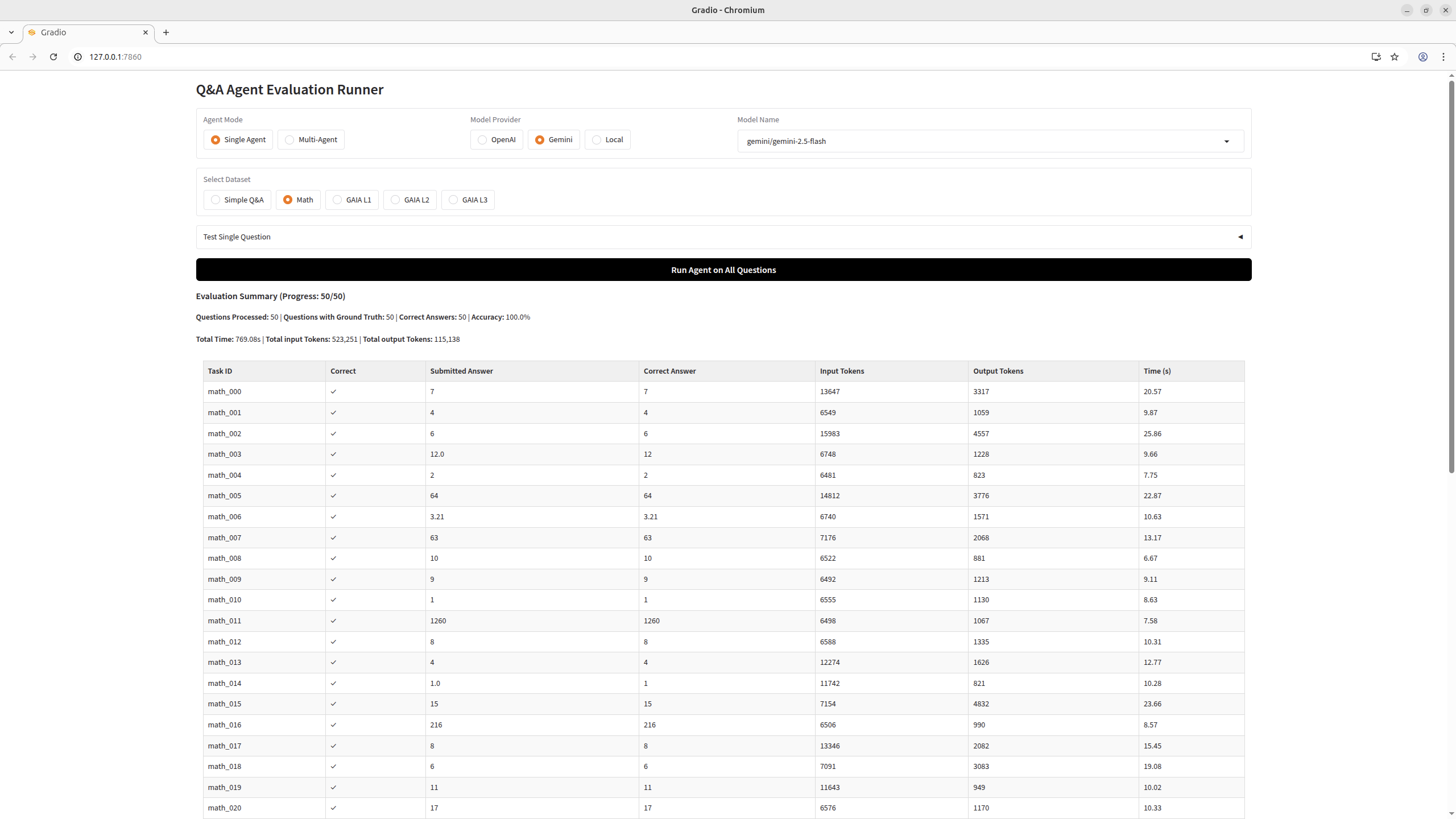
Results
| Model | Agent | Score |
|---|---|---|
| Gemini-2.5-flash | Code Agent | 50/50 |
| Qwen3.5-4B | Code Agent | 48/50 |
| Nemotron-3-Super-120B-A12B-NVFP4 | Code Agent | 50/50 |
GAIA-1
Questions from the GAIA benchmark GAIA evaluates AI assistants on real-world tasks requiring multi-step reasoning, tool use, and file handling.
Three difficulty levels:
- Level 1: Generally requires 1–2 tools and few reasoning steps
- Level 2: Requires combining multiple tools with more complex reasoning
- Level 3: Requires long chains of actions, advanced reasoning, and diverse tool use
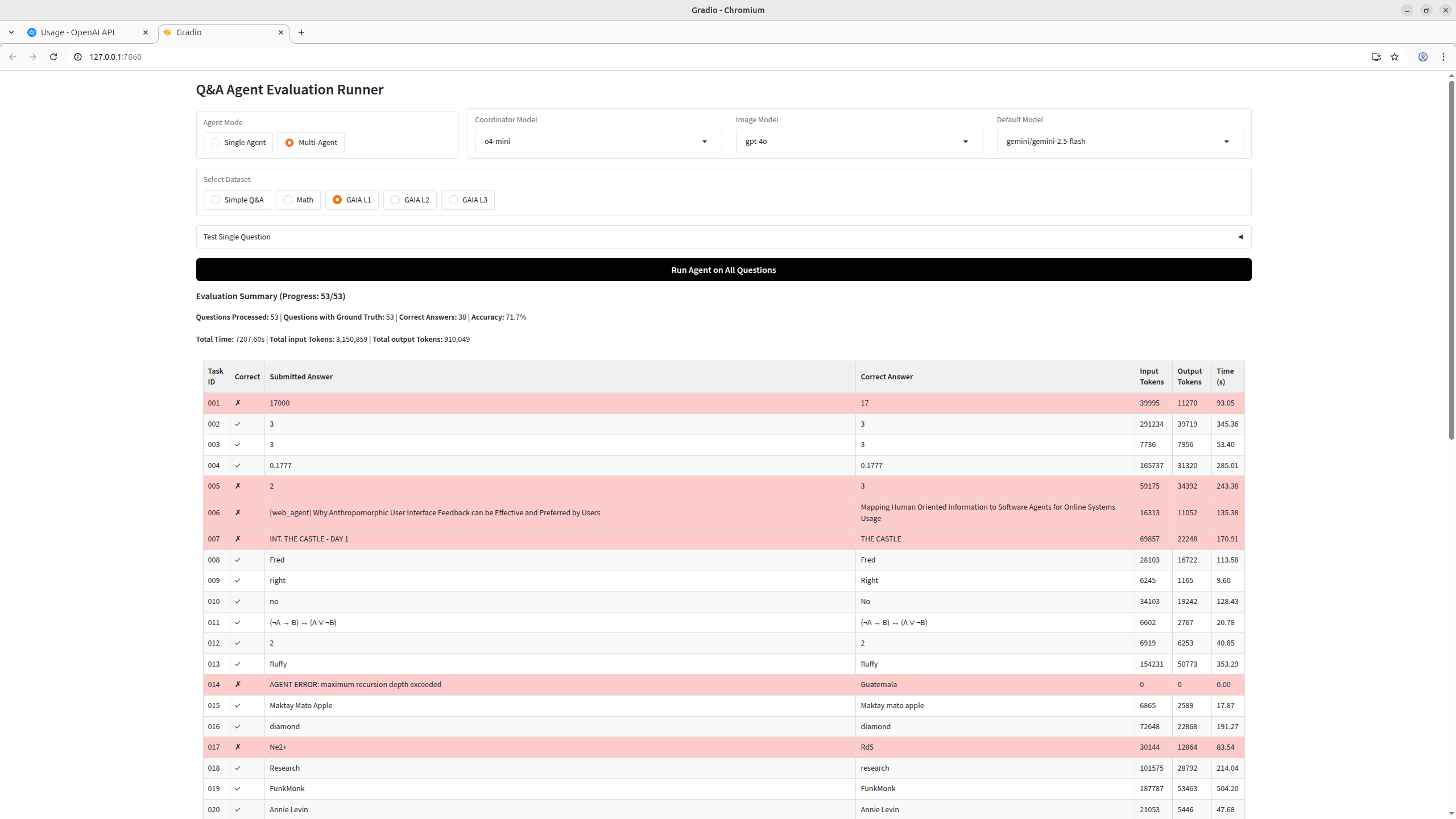
Results
| Model | Agent | Score |
|---|---|---|
| o4-mini / gpt-4o / Gemini-2.5-flash | Multi-Agent | 38/53 |